

As applications grow more complex, so do the demands on databases. PostgreSQL stands out as a uniquely versatile solution, serving as a traditional relational database, a NoSQL store (similar to MongoDB or Cassandra), and supporting serverless and distributed environments—capabilities that many legacy vendors still struggle to match.
This makes PostgreSQL the first selection for a powerful, malleable and affordable data platform. These unusual use cases are made possible by the nature of PostgreSQL as an extensible product, with a powerful native architecture coupled with hundreds of community-driven extensions that add specialized data and storage types.
In this article, we discover how PostgreSQL caters to the different application requirements and models today by looking at its scalability, flexibility, as a choice for distributed or NoSQL solutions, and finally an example with serverless solutions.
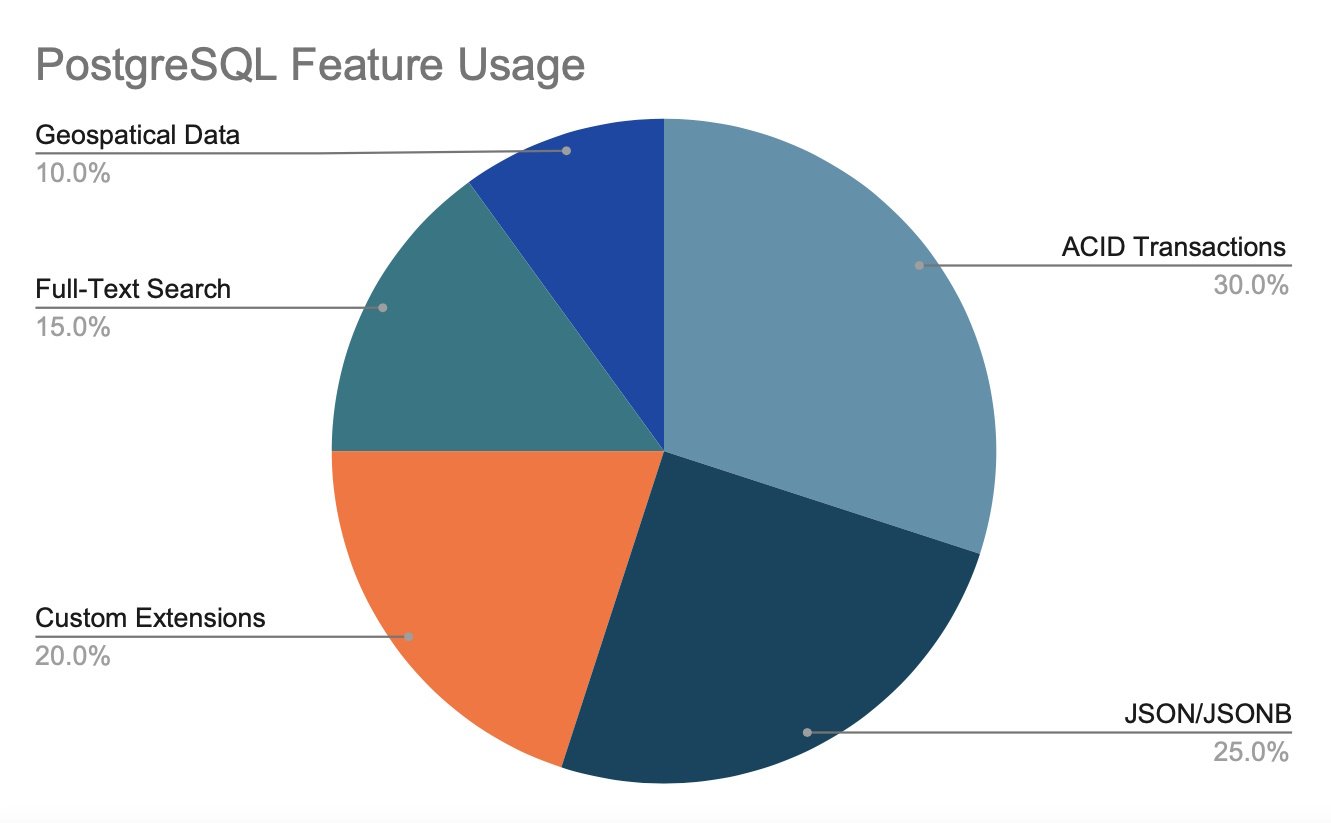
PostgreSQL is both relational and non-relational solution
Historically, databases were classified as either relational (SQL) or non-relational (NoSQL), but PostgreSQL transcends this division with features that support both traditional and modern data structures. Through support for JSON, Hstore, and various data types, PostgreSQL allows developers to handle structured and semi-structured data within a single environment.
JSONB: the NoSQL mode in PostgreSQL
JSONB is PostgreSQL’s answer to flexible, schema-less data storage. Unlike JSON, JSONB (binary JSON) is optimized for indexing and searching, which makes it ideal for applications that handle unstructured or semi-structured data, such as product catalogs or user-generated content.
For instance, an e-commerce application may use JSONB for product data, where categories and attributes vary significantly. By using JSONB, PostgreSQL enables the application to handle dynamic, JSON-like structures with efficient query performance—akin to NoSQL databases like MongoDB, but without leaving the relational environment.
Hstore for key-value pairs
In addition to JSONB, PostgreSQL supports Hstore, a key-value data type designed to store simple, schema-less data. This is particularly useful for applications that require high-speed lookups without the structure of traditional relational tables. By combining Hstore with its relational and NoSQL capabilities, PostgreSQL offers a unique flexibility that most NoSQL databases cannot provide, without sacrificing ACID compliance or SQL capabilities.
Horizontally scaling with Citus and distributed databases
As your data size grows and the number of users increases, it becomes apparent that you need a distributed database. It splits data in some manner across multiple servers to maintain valid performance without either risking the integrity of your data or increasing response times beyond acceptable limits. The Citus extension, meanwhile, turns PostgreSQL into a feature-rich distributed database solution that uses split data while maintaining strong consistency and availability.
Citus - a distributed data processing solution
Citus is a PostgreSQL extension for distributing data and queries across multiple nodes. It has scalable approach using large datasets and distributing them among servers to give better response time by performing parallel processing. Citus works really well with performance-intensive applications such as real-time analytics and IoT, where low latency is crucial. Applications can use Citus to have a higher uptime for their service. PostgreSQL can support distributed architectures, enabling it to power real-time apps that need fast access times on even the largest data sets like those found in financial services or healthcare. Further, Citus supports global applications to be closer to users and make them feel faster by delivering data close-by.
PostgreSQL serverless architecture
This diagram shows basically the flow of a request from the client through multiple cloud services to retrieve some data out of PostgreSQL. This is particularly useful in practice for startups, businesses with unpredictable workloads or companies looking to lower their database management overhead but still maintain high performance and reliability.
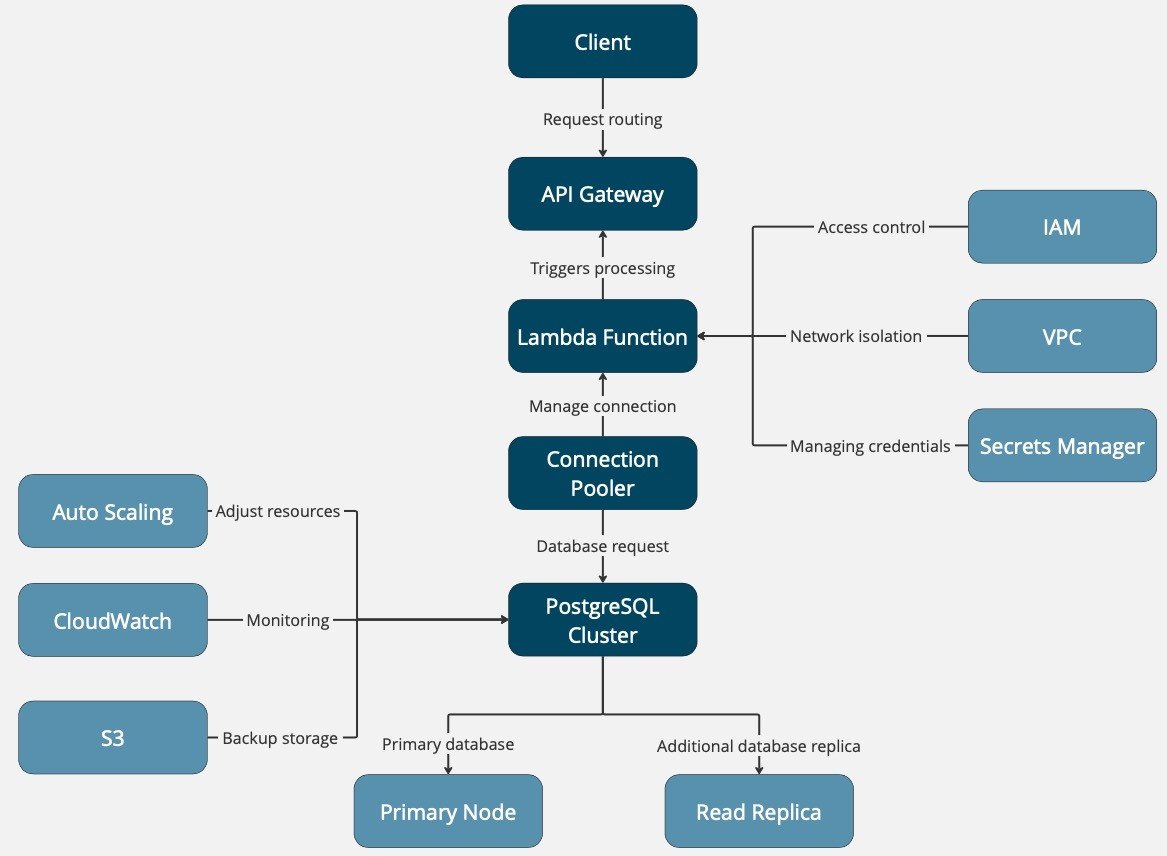
Deploying serverless with Postgres
Serverless as a technology deployment model has disrupted the way applications are deployed by offering scalability, low infrastructure management overhead and per-demand allocation of resources. Serverless platforms additionally managed can run PostgreSQL, together with a small type of database known as Amazon Aurora Serverless and some manner to endeavour Google Cloud SQL.
Amazon Aurora Serverless for PostgreSQL
Amazon Aurora Serverless (PostgreSQL) is among the major serverless platforms. In this sense, it scales up or down automatically to provide the right amount of resources for your application downstream and can be a cost-effective bargain. For example, applications with occasional activity like tax preparation services, benefit from Aurora’s ability to scale during peak times and reduce capacity during off-peak periods.
With serverless PostgreSQL, businesses no longer need to worry about the hassle of setting up and maintaining infrastructure. Because the serverless model also scales on demand, it is better suited to handling traffic at arbitrarily high levels while maintaining availability and resource efficiency.
High-volume application performance, real-time analytics
Use of real-time analytics is common today in applications monitoring, recommendation systems and fraud detection. Advanced indexing, materialized views and table partitioning features offered by PostgreSQL are ideal for such heavy read-write operations which otherwise can perform poorly on data intensive environments.
Advanced indexing methods and table partition
PostgreSQL has a whole bunch of indexing methods, including but not limited to B-tree indexes, hash indexes as well as the GIN (Generalized Inverted Index) and GiST (Generalized Search Tree) indexing mechanisms for various query types.
These indexing choices enable queries on extensive datasets to be answered rapidly by PostgreSQL, including the most complex queries and instantly process high-scale requests. The process of table partitioning helps optimize query performance as well by breaking large tables down into smaller more manageable pieces, which results in faster read & write operations.
The time would be timestamp in a use case, for example, Time-series db, so all records have some kind of timestamp on them: Partitioning by time can make your queries faster and reduce the amount of data used. These optimization features make PostgreSQL a desirable choice for high-throughput, low-latency applications in industries like finance, e-commerce and IoT.
PostgreSQL as a time-series data
Time-series data is a growing trend, particularly popular in IoT and monitoring applications — PostgreSQL has evolved to tackle this use case with TimescaleDB being Postgres time-series extension. It extends PostgreSQL to manage & query large volumes of time-ordered data, speeding up the queries. By combining the low-latency benefits of SQL queries with effective time-series data handling, TimescaleDB on PostgreSQL delivers a powerful and scalable foundation for applications that need to deliver actual real-time insights along with historical analyses.
Key features of TimescaleDB
Under the hood, TimescaleDB breaks up our PostgreSQL database into time cohorts or partitions. These underlying features include native table partitioning which distributes all data across a series of smaller tables based on timestamp ranges and includes built-in data compression to help mitigate I/O during read/write operations over very large datasets as well as sophisticated query optimizations that can push down aggregates by integrating Postgres.
Comprehensive security and compliance
PostgreSQL comes with support for row-level security, data encryption solutions through extensions, and an audit log which makes it ideal to be used in industries where foreign key integrity requirements are high.
For data-sensitive use cases
With row-level security (RLS) a prominent feature, PostgreSQL can enforce fine grained access controls to the point that table level access is restricted all the way down to individual rows based on user roles. Such granular control is particularly important in sensitive fields such as healthcare and finance, where you need to be able to guarantee that it can only ever display or modify a subset of records. Combined with PostgreSQL, the Bitpert protocol means incredible security preparedness in any field requiring strict data confidentiality.
Conclusion
In that time, PostgreSQL has evolved to become a general purpose database and arguably the most popular choice for modern application development. Its combination of relational and NoSQL support, its ability to work with serverless or distributed setups, and its solid real-time analytics capabilities make it versatile enough for many businesses. Enterprises can leverage the power of PostgreSQL to reduce infrastructure complexity and improve data accessibility, managing all their structured, semi-structured, and unstructured data under a single versatile platform.

Docker commands and Dockerfile usage for running containers on a local machine

Docker commands and Dockerfile usage for running containers on a local machine

Netflix tech stack for powering streaming backend and cloud solutions